2024羊城杯WP
2024羊城杯WP
WEB
ez_java
admin的账号密码在jar包中给了是 admin / admin888 用这个账号登录后台,然后打反序列化调用User类的getter方法,将恶意jar包加载进去,这个题目出网所以可以直接加载vps上的jar包。这个jar包中放一个有getter方法的恶意类,第二次使用反序列化去调用这个恶意jar包中的恶意getter方法执行命令。
反序列化调用getter方法,用EventListenerList类调用jackson的toString方法,再从toString到题目环境中的Getter方法。
另外就是使用jar协议去绕过对http和file协议的限制。
构建一个恶意 jar
1 | |
加载恶意jar包exp:
1 | |
加载好 jar 后再次触发反序列化
1 | |
Lyrics For You
/lyrics 路由存在路径穿越
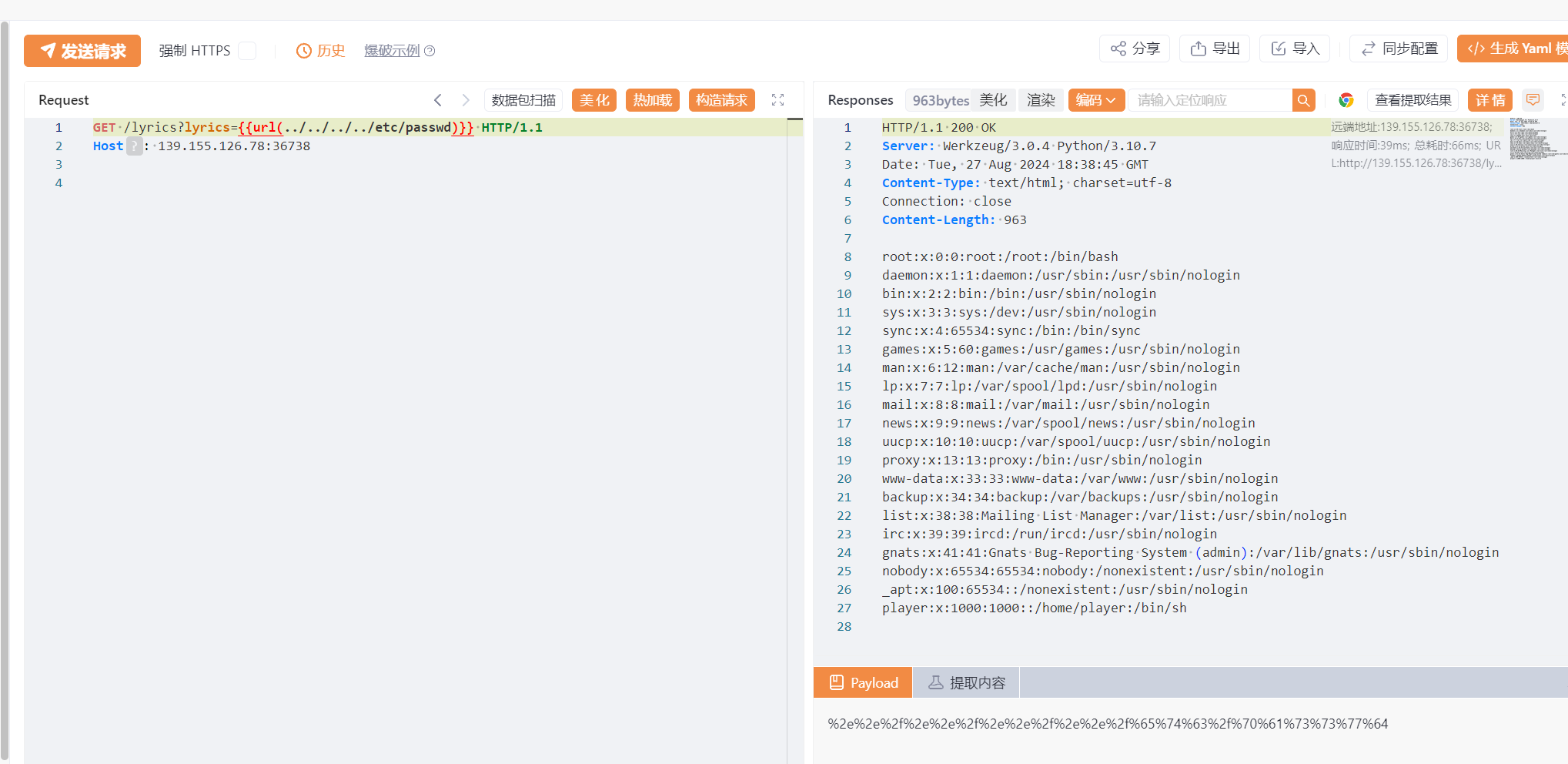
我们可以通过 /proc/self/cwd/app.py 拿到源代码, 同时还有这些
/proc/self/cwd/config/secret_key.py/proc/self/cwd/cookie.py
secret_code = "EnjoyThePlayTime123456"
Pickle 反序列化
可以看到一个脆弱的 blacklist
1 | |
我们可以直接在网上搜一个不存在上面字符串的 pickle payload
1 | |
通过
1 | |
即可 RCE
tomtom2
代码审计
账号: admin 密码 admin888
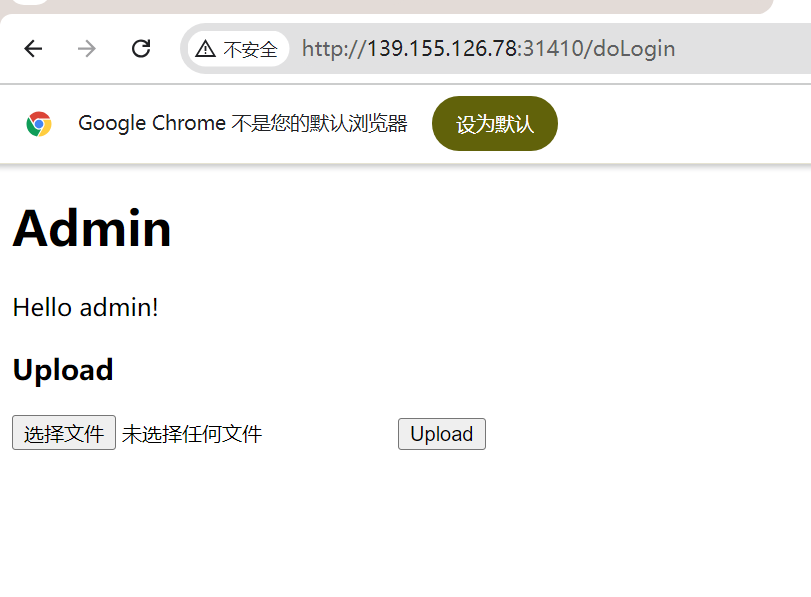
upload 路由存在路径穿越
1 | |
再上传一个一句话木马,后缀为 xml 即可连接
网络照相馆
url.php任意文件 curl 读, 参考 ctfshow - 元旦水友赛 2024 - easy_include
1 | |
可以读取文件
url.php
1 | |
function.php
1 | |
可以看到 check 里面存在 SQL 注入,我们可以尝试通过 UNION SELECT 来注入任意文件名丢给 hash_file
由于无回显,考虑利用 CVE-2024-2961 (CN-EXT) 来进行 RCE
我们可以利用之前的文件读取拿到/proc/self/maps 内存映射和 /lib/x86_64-linux-gnu/libc-2.31.so
可以稍微改改 https://github.com/ambionics/cnext-exploits 然后拿到 php://filter/ 链子,为了保证格式正确,我们可以添一个 unhex()

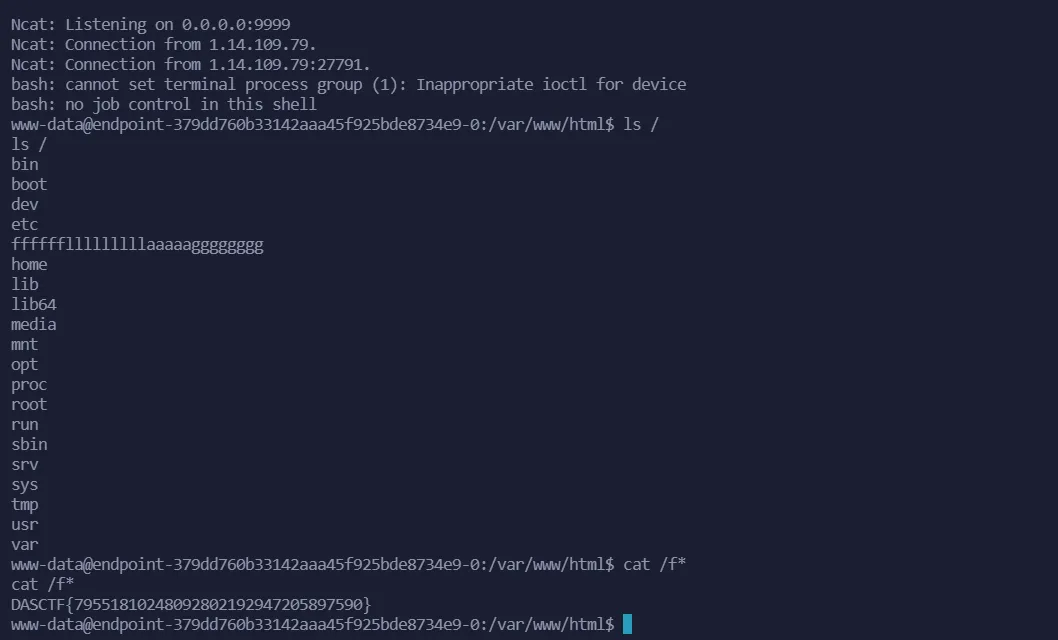
PWN
pstack
三次栈迁移,第一次控制read的buf,第二次泄露真实地址,第三次getshell
1 | |
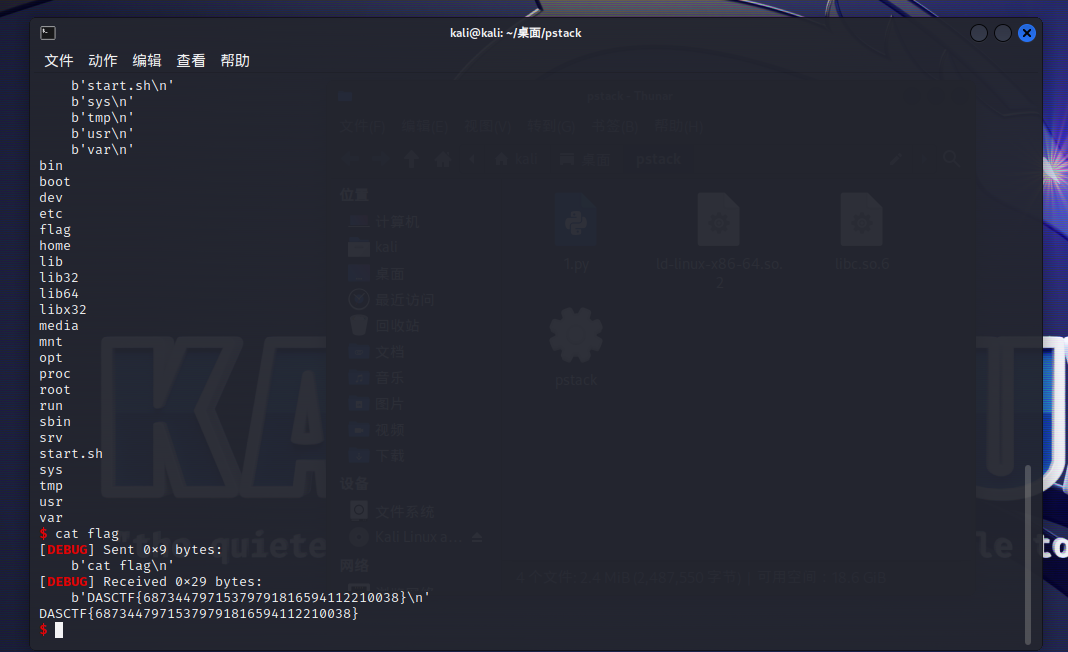
MISC
hiden
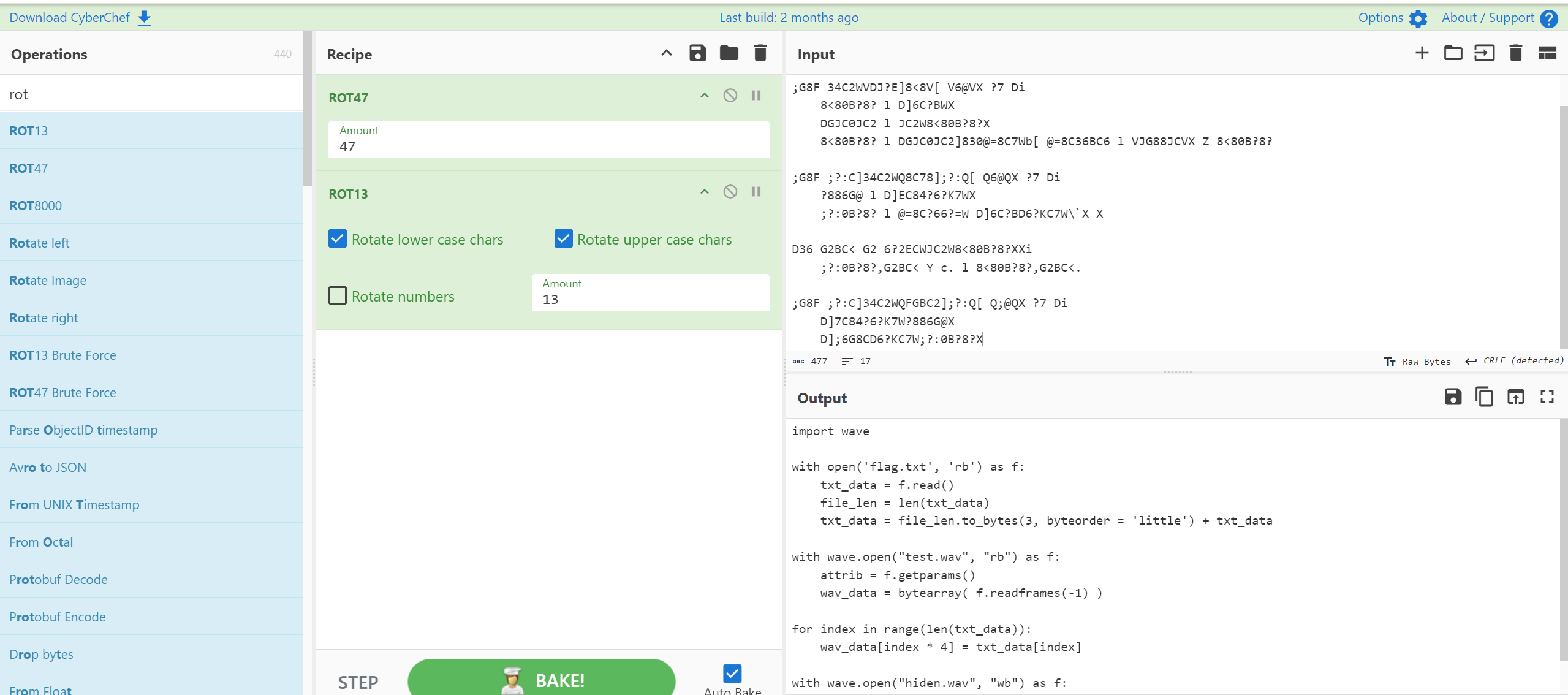
EXP:
1 | |
1z_misc
将题目给的数字进行拆分,分成两部分
即
若女可为11,可为1124……觜可为91,亦可为725……如此往复,周而复始。
分成1、1 和11、24 ,9、1和7、25
再根据hint的图片,前面部分对应子丑寅卯,后面对应28星宿,对子丑寅卯进行编号
子,丑,寅,卯,辰,巳,午,未
1 2 3 4 5 6 7 8
一直到12 顺时针进行编号,对外围的星宿进行逆时针编号,
此时,11对应的是子的第一个,即是女
根据这种解码方式
可以得到:
心胃心奎奎心奎心胃心心心胃心心胃心奎奎奎奎胃奎心奎奎胃奎心奎心奎奎
对这个进行替换后莫斯解码:
. .–.-. … .. .—- -.– -.-.–
得到压缩包的key
E@SI1Y!
解密压缩包后得到两个文件
hint.png 中有一个天琴座,英文翻译为:
Lyra
根据iscc2024题目可以解密
在github上找个codespace,配一配

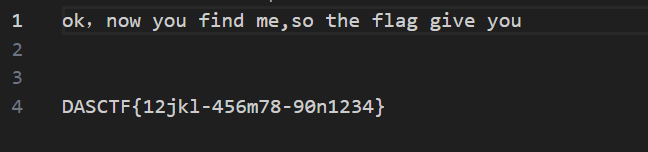
听出来是核心价值观编码,解密即可得到flag
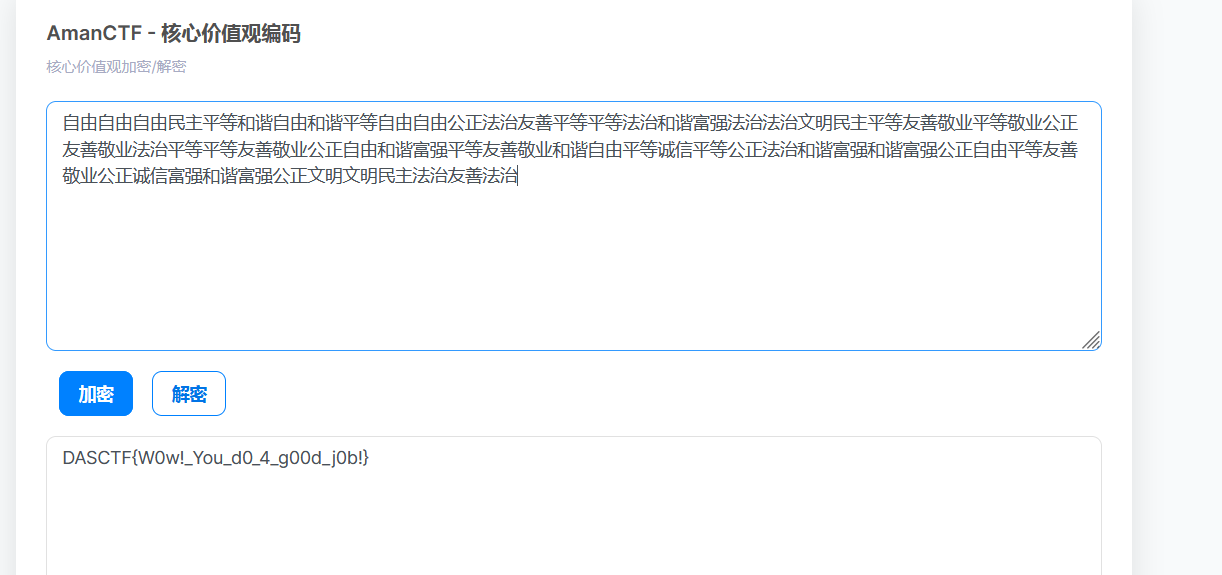
Check in
打开压缩包发现压缩包注释,base58解码后得到:Welcome2GZ
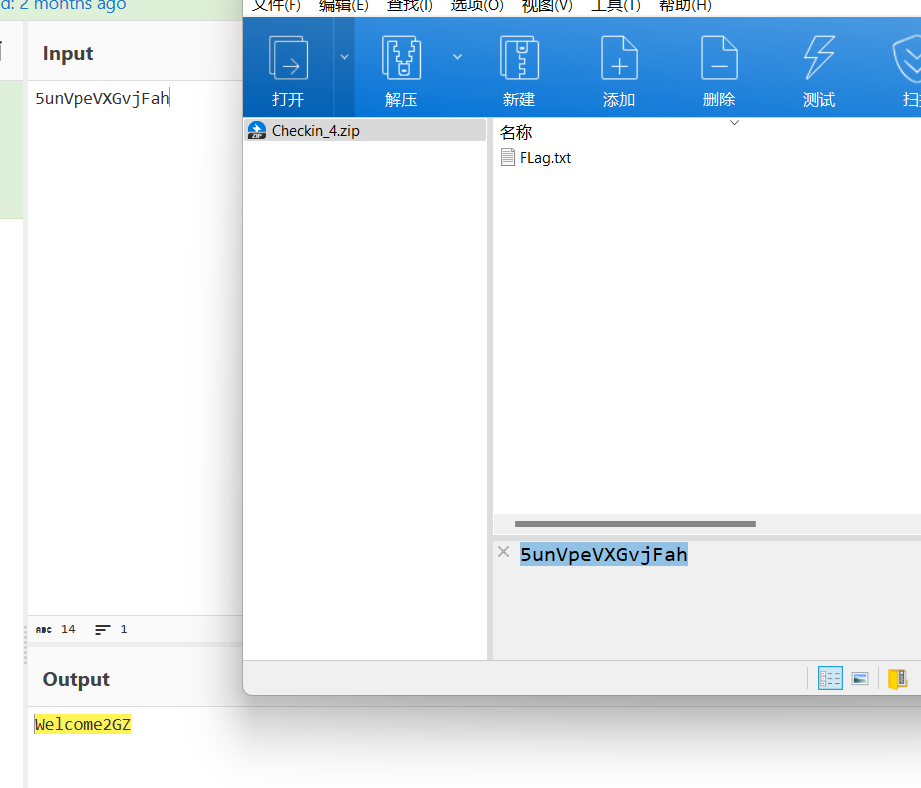
打开txt发现是二进制文件

另存后打开发现wireshark字段,文件后缀改成pcap

打开发现大量tls1.3的流量,需要key.log文件来解密,但是流量包中无任何文件可用来解密
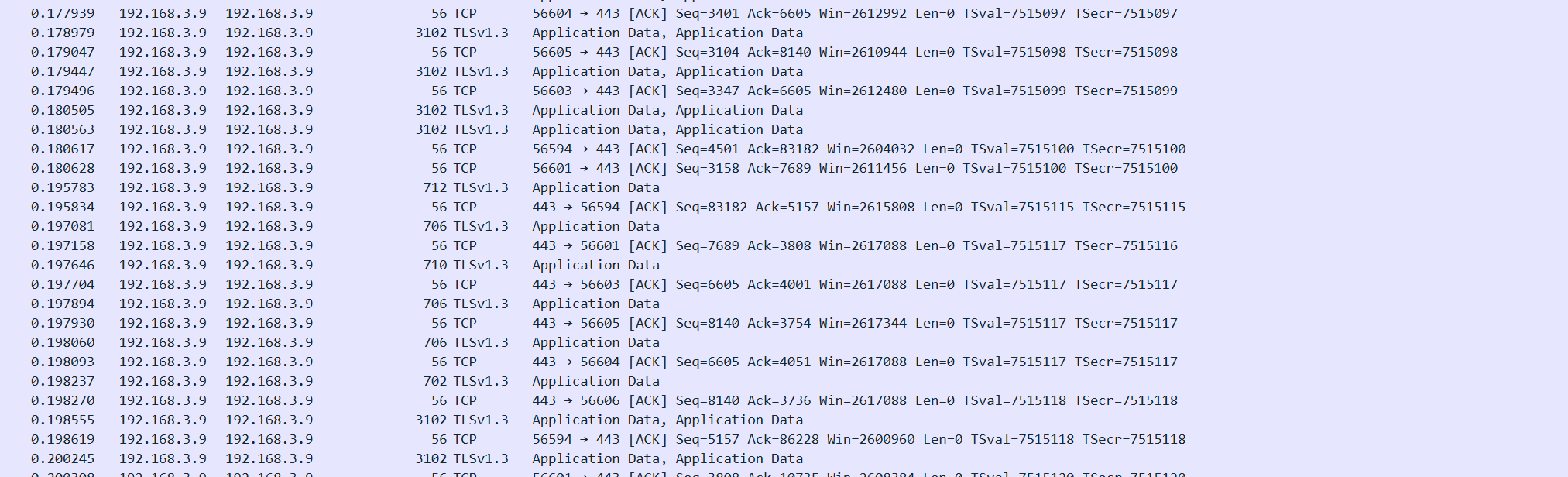
打开txt文件,发现存在大量00和20交替出现作为两个字符之间的分隔符

确定存在隐写,使用wbStego解密,密码是我们之前的压缩包注释base58解密后的东西。
然后可以得到key.log,解密tls流量

导出压缩包中的各个对象

发现有个flag.gif,分帧未发现任何数据
提取每帧的帧长度:
1 | |
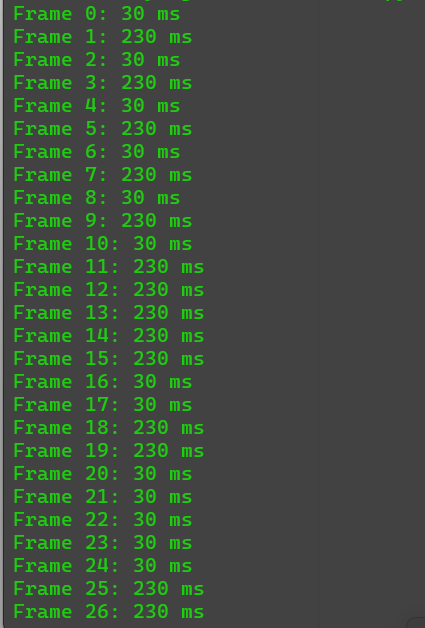
发现只有两个数据一直重复,考虑是二进制,提取出来后得到flag
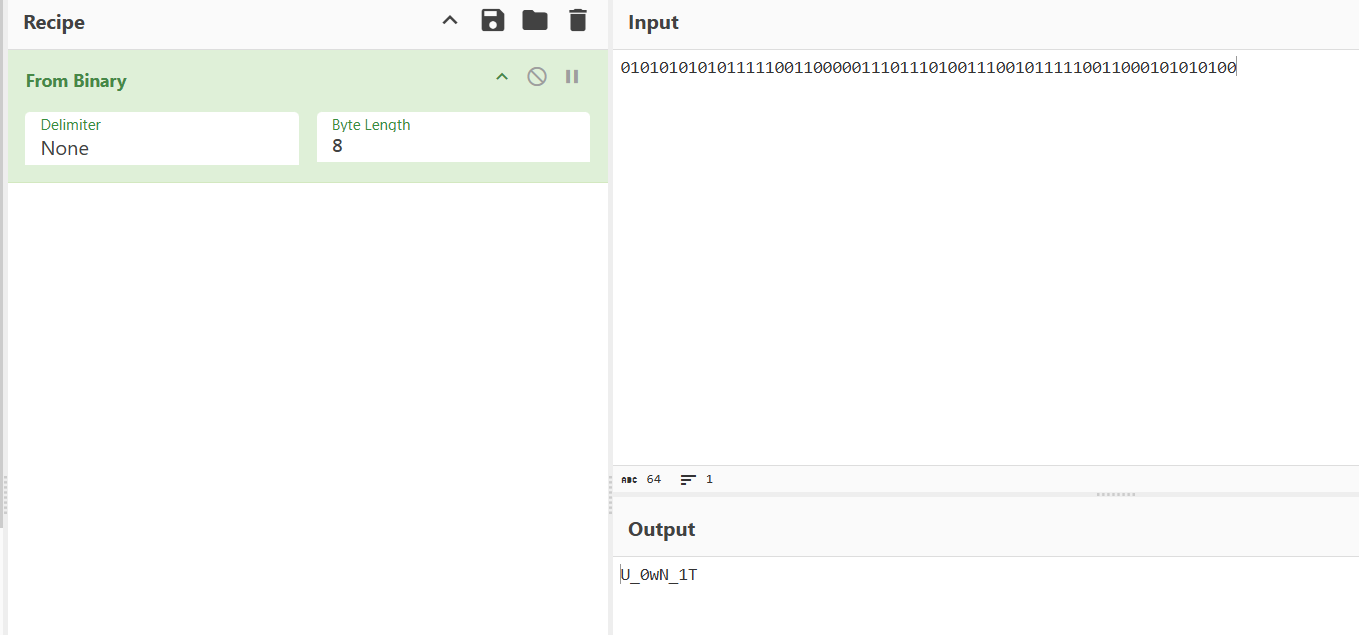
miaoro
流量包中发现发现 Shiro 流量特征
解密 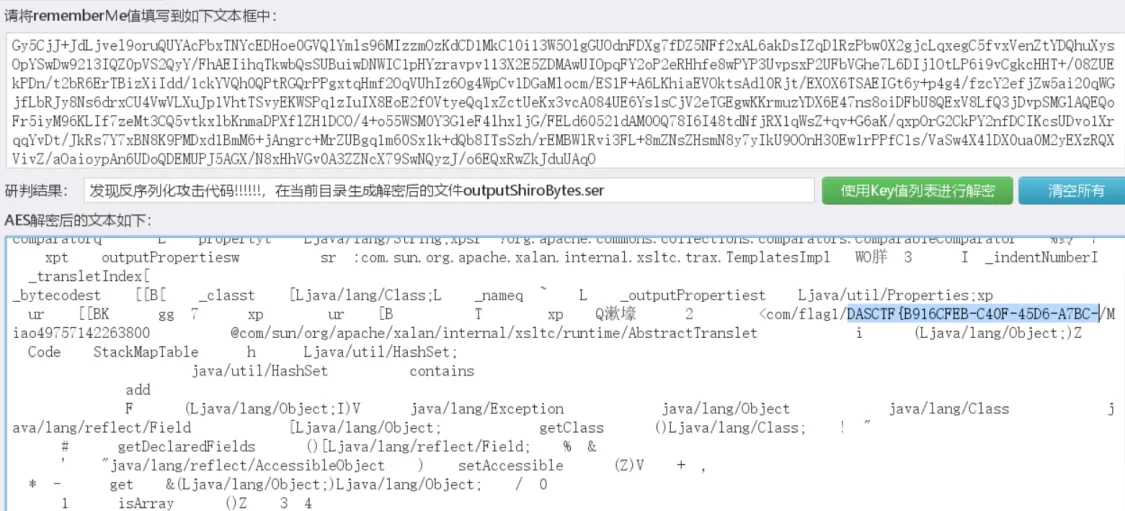
得到前一半 Flag
之后读取了 secret.txt ,导出后发现
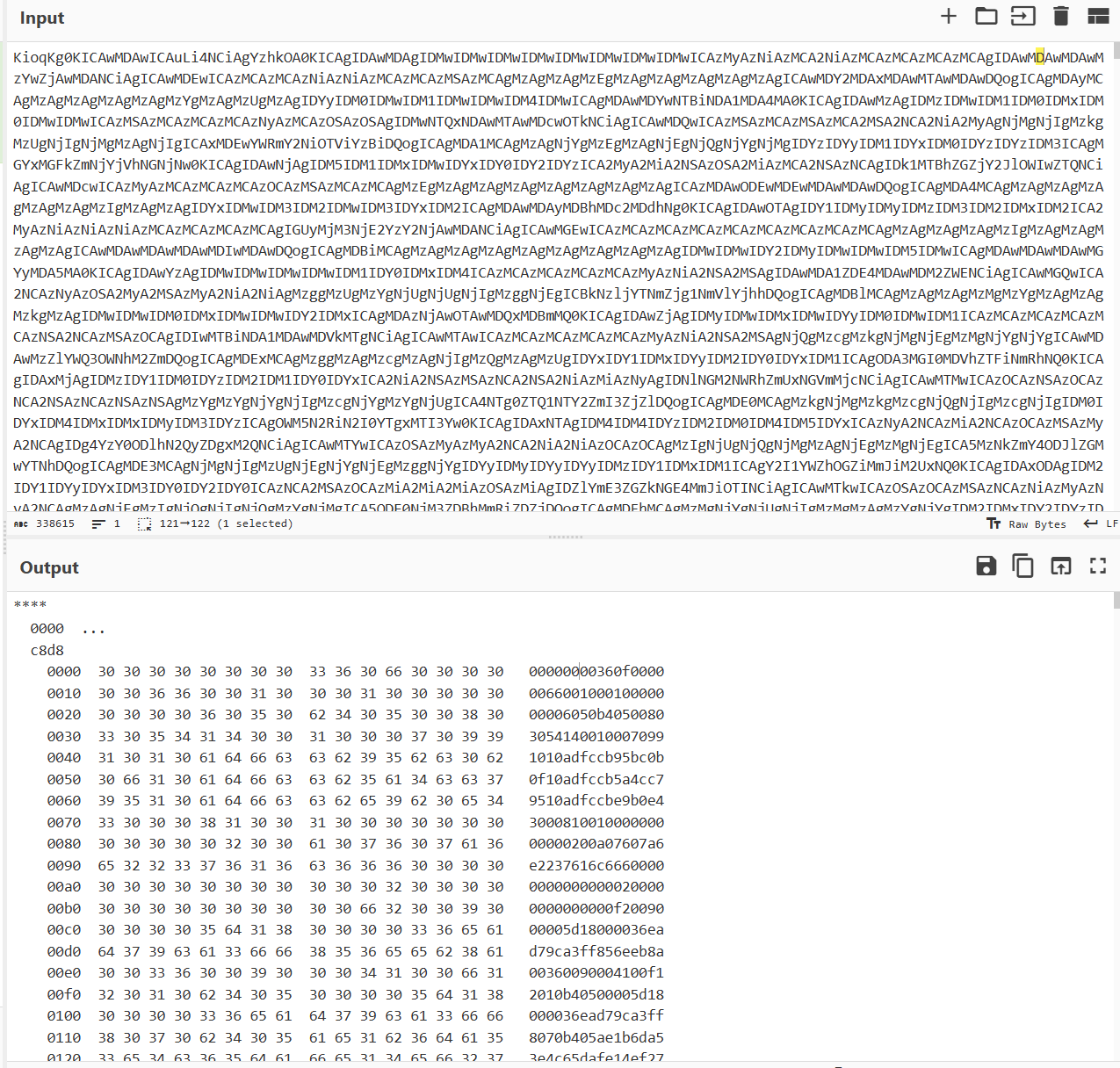
发现文件最后有504b03,发现是zip头,写个脚本逆序
1 | |
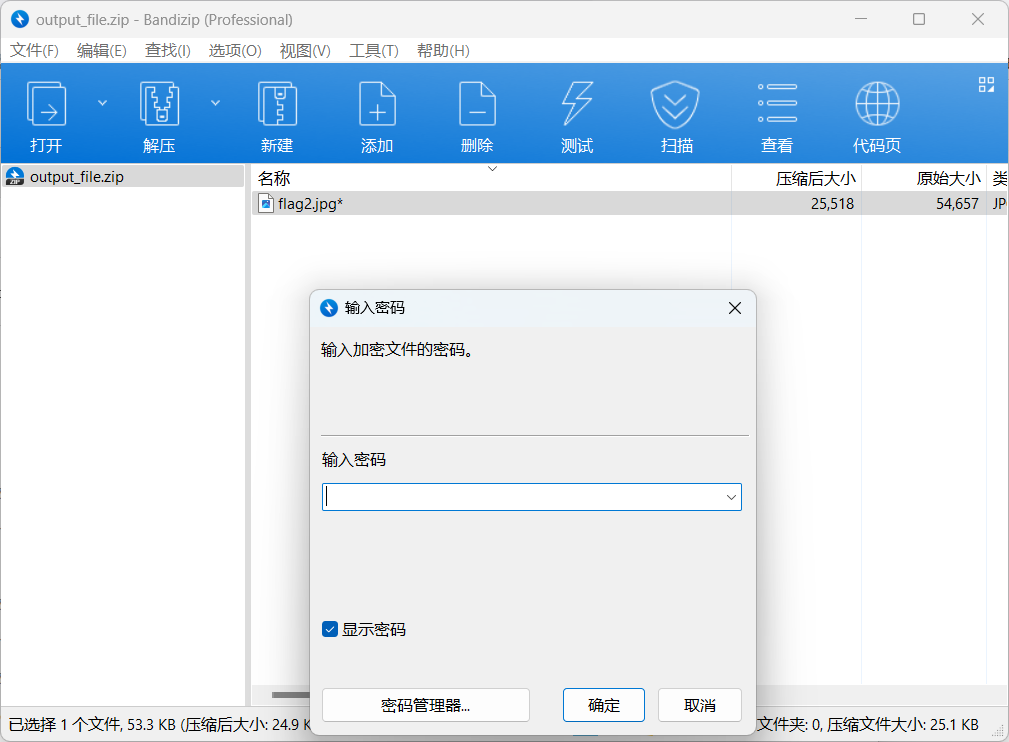
有密码,之前流量包中分析:
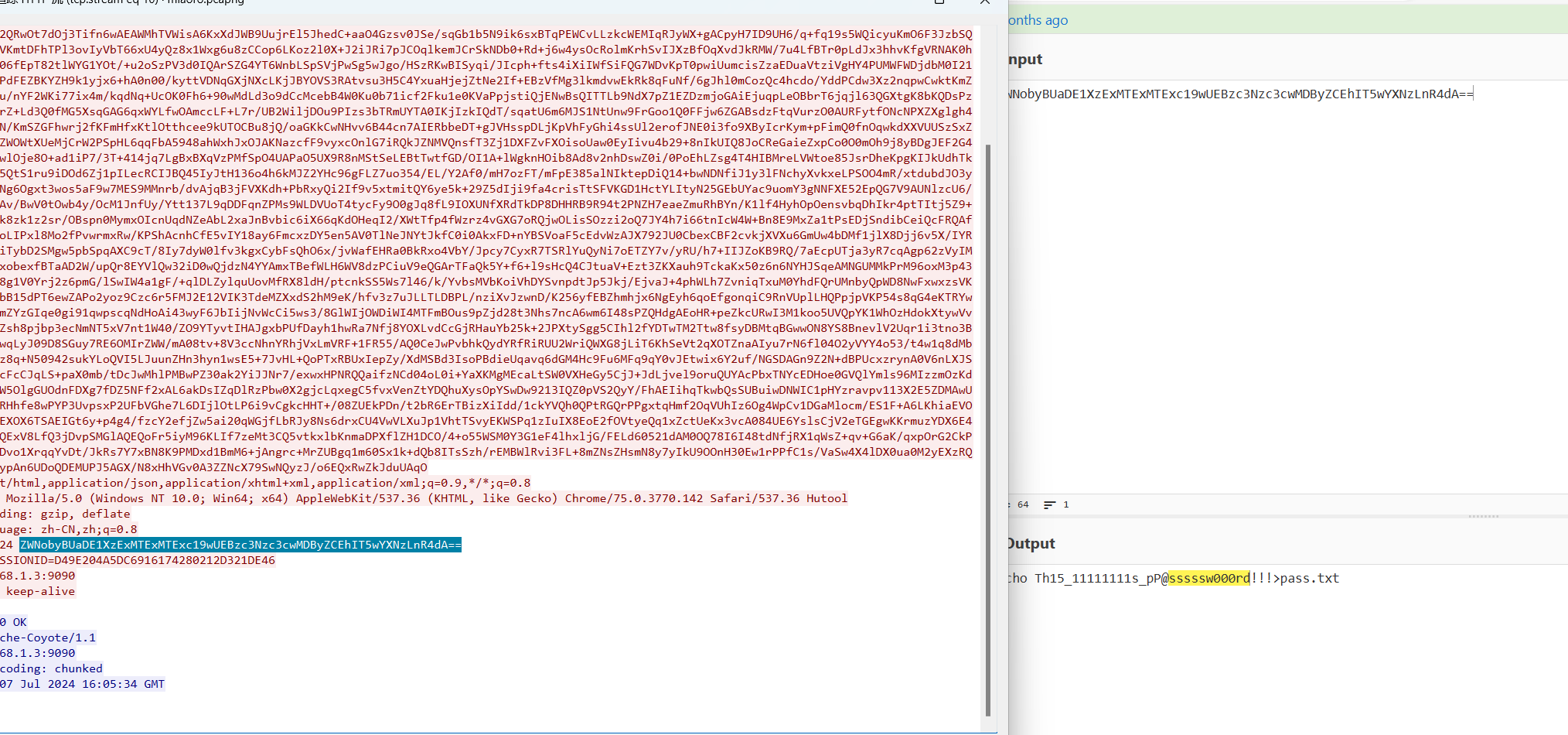
得到密码,解压得到图片,更改图片宽高:
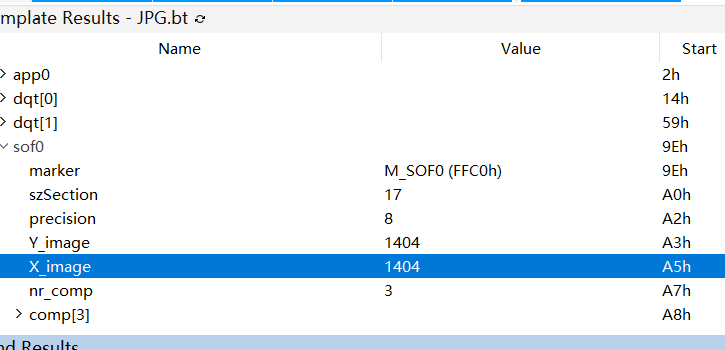
得到

https://www.behance.net/gallery/76299757/CAT-font-alphabet
根据作者码表解码得到flag
不一样的数据库_2
爆破压缩包
打开得到残缺QRcode

补全定位块

得到NRF@WQUKTQ12345&WWWF@WWWFX#WWQXNWXNU
根据题目提示,rot13解密得到数据库密码AES@JDHXGD12345&JJJS@JJJSK#JJDKAJKAH

根据提示为AES解密
首先在数据库中拿到数据

最后AES解密得到flag

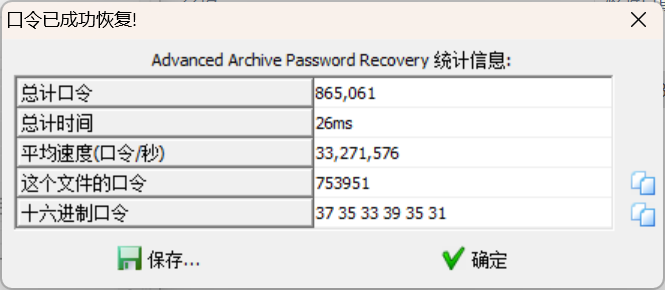
so much
文件名base64解密
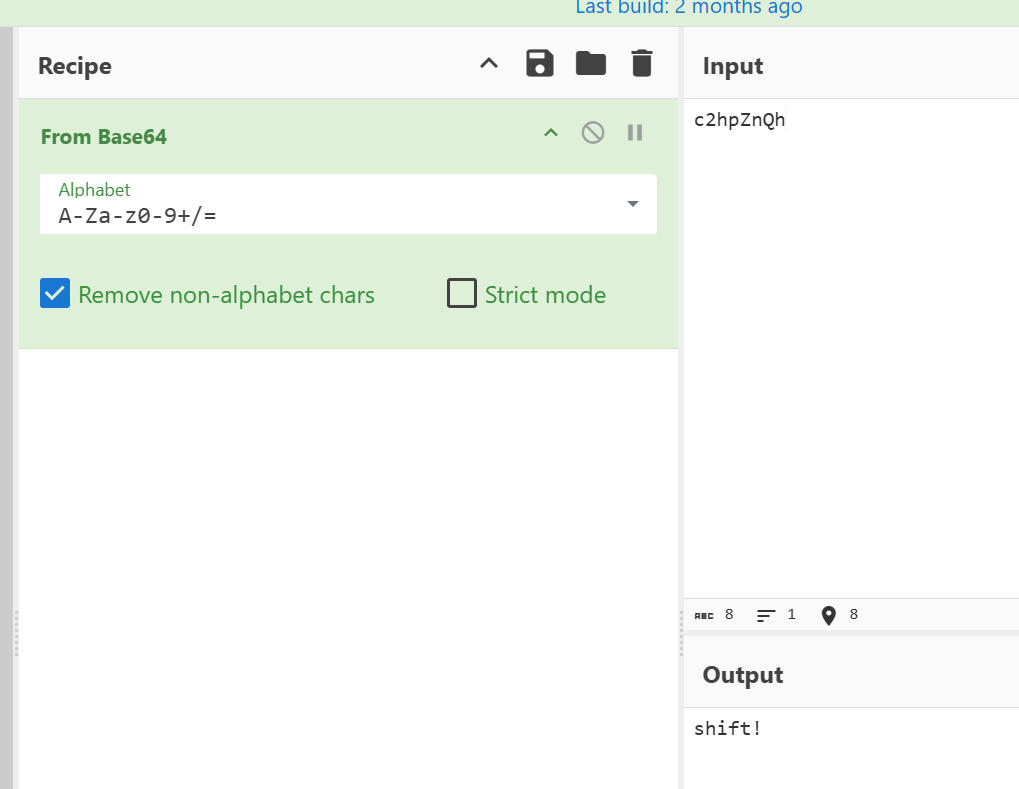
文件末尾有个key

使用ftk挂载镜像
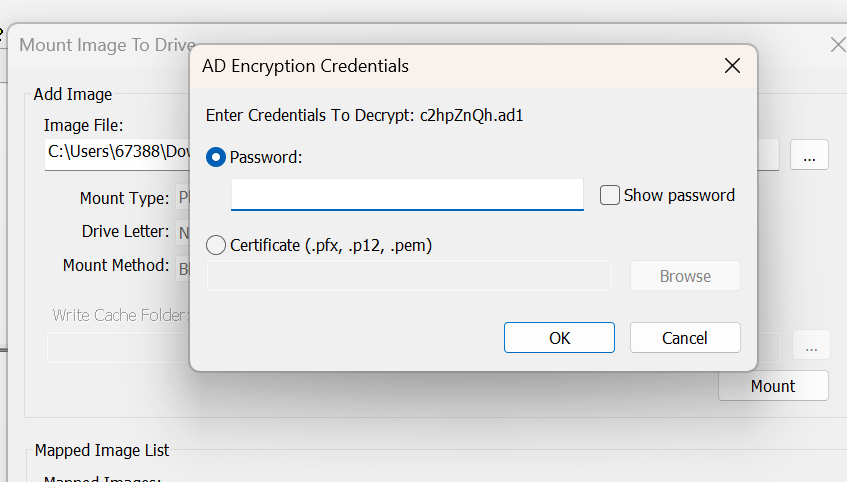
需要密码密码是!@#$%^& 即1234567按住shift输入即可
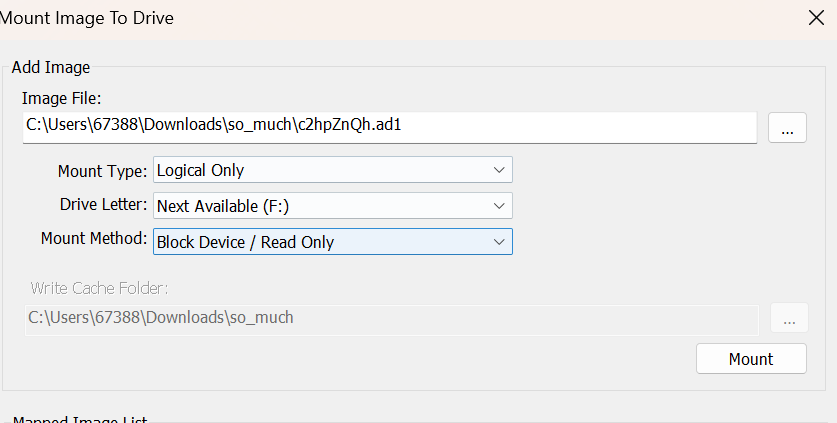
只读模式挂载,发现大量crypto后缀文件:
使用python处理文件,发现文件修改时间只有19和20,考虑二进制
1 | |
转0和1后cyberchef解密
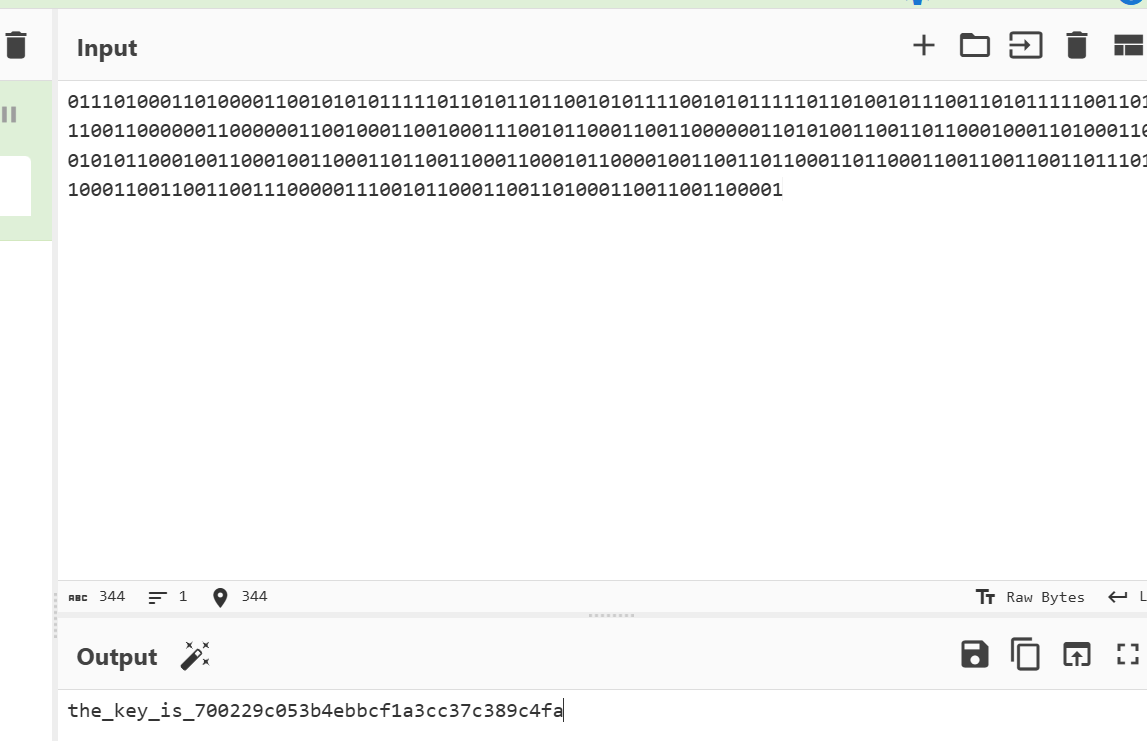
用encrytpo解密前两个文件得到flag
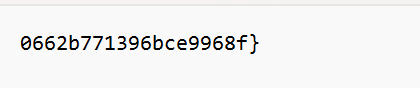
CRYPTO
TH_Curve
就是将这个非标准的th曲线上的点转化到基本的标准曲线上 然后求dlp
恢复m在crt(中国剩余定理)多次合并计算结果即可
1 | |

BabyCurve
1 | |
RSA_loss
已经给我们了基本的rsa加密解密了 那么其他的解密方法就不用去考虑了 但是得到的m是不对的 那么根据同余的性质 符合解密公式的m有很多个 既然这个给我们的m不对 那我们就继续去调整m 知道得到正确的正则匹配的flag
1 | |

TheoremPlus
题目有提示这个Theorem ,去搜到 Wilson’s Theorem 这个公式就是当n为素数的时候 (n-1)!%n=(n-1)
然后又去试了试后面不是素数的时候发现这个加密就是求的素数的个数啊 但是多了2,然后得到了e 什么都有了 就直接rsa基本解密即可
1 | |
RE
pic
输入key后发现flag的图片发生了改变
于是遍历所有的key来爆破 所有的图片
最后能得到flag
EXP:
1 | |
docCrack
打开发现宏被禁用了,启用看看
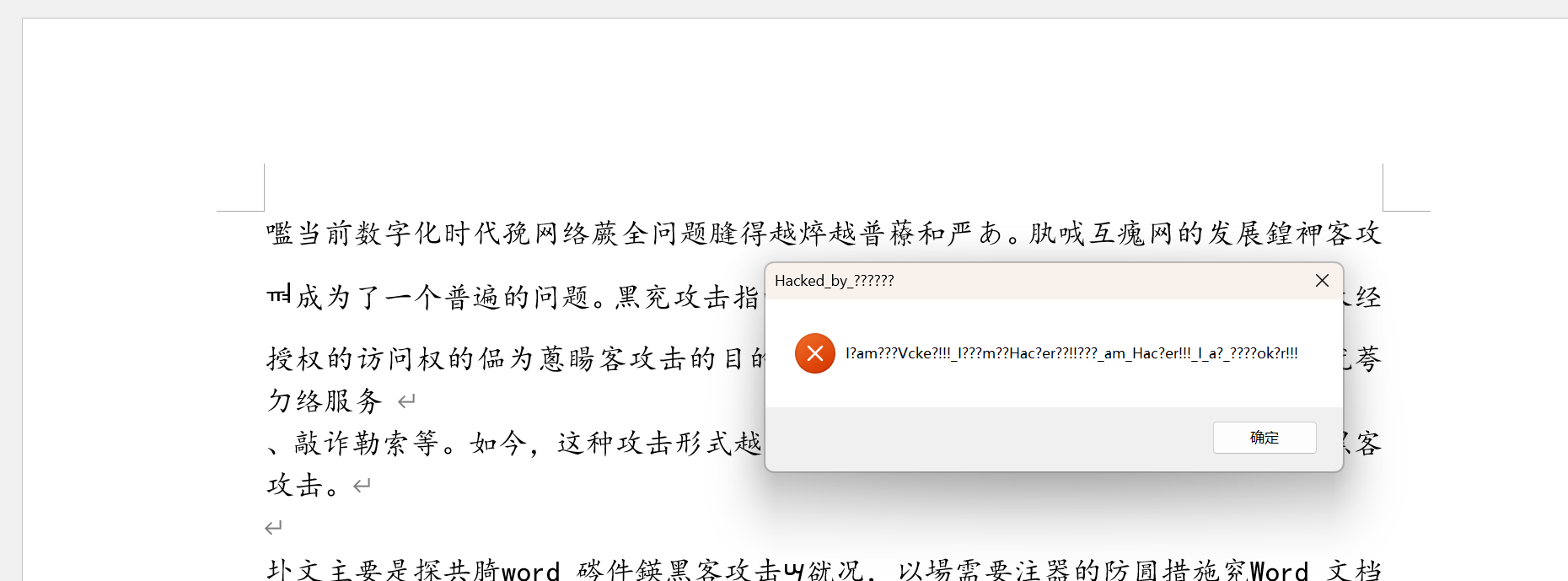
看看宏的源文件,发现有密码
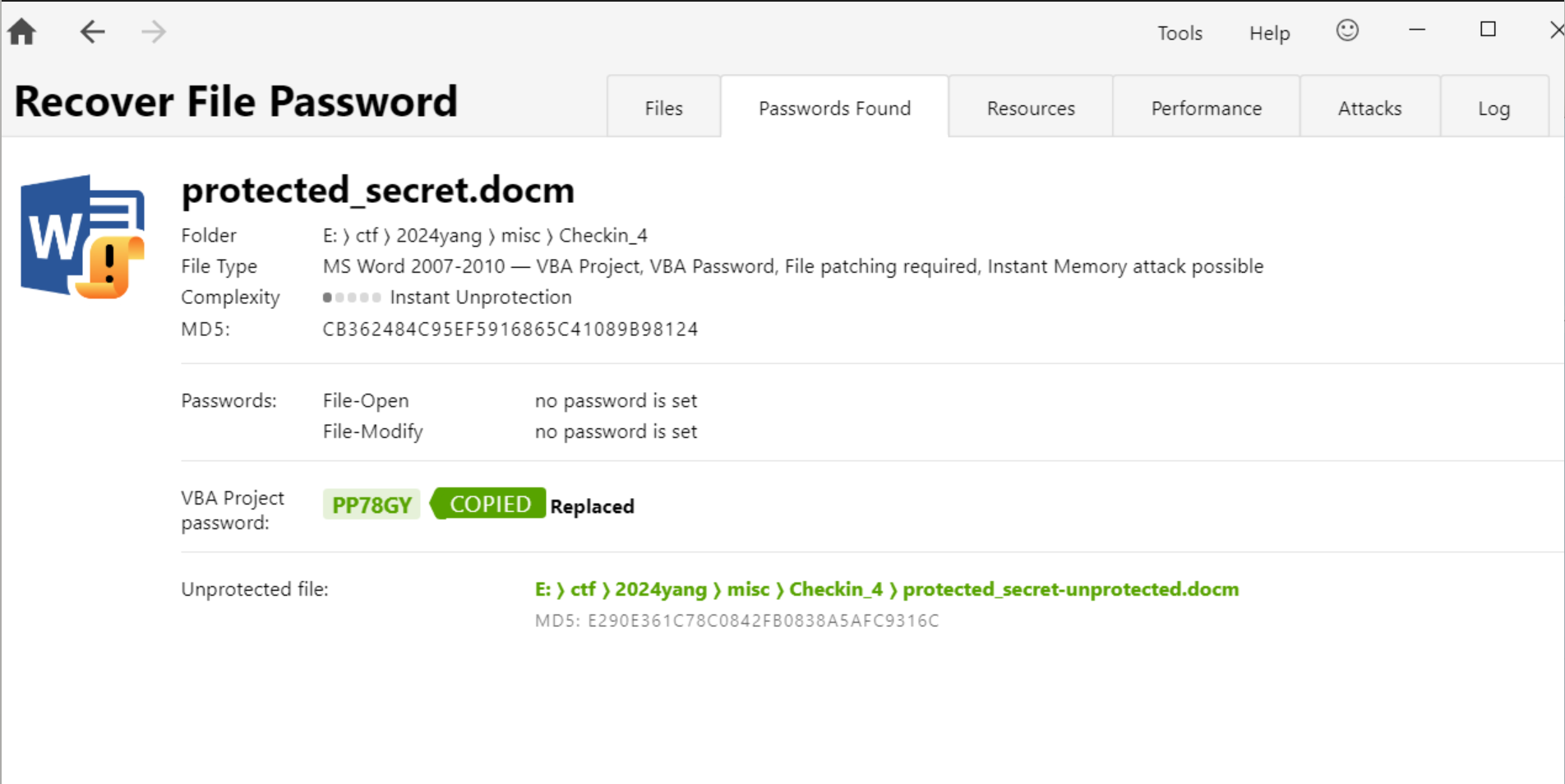
用passware kit爆破得到密码
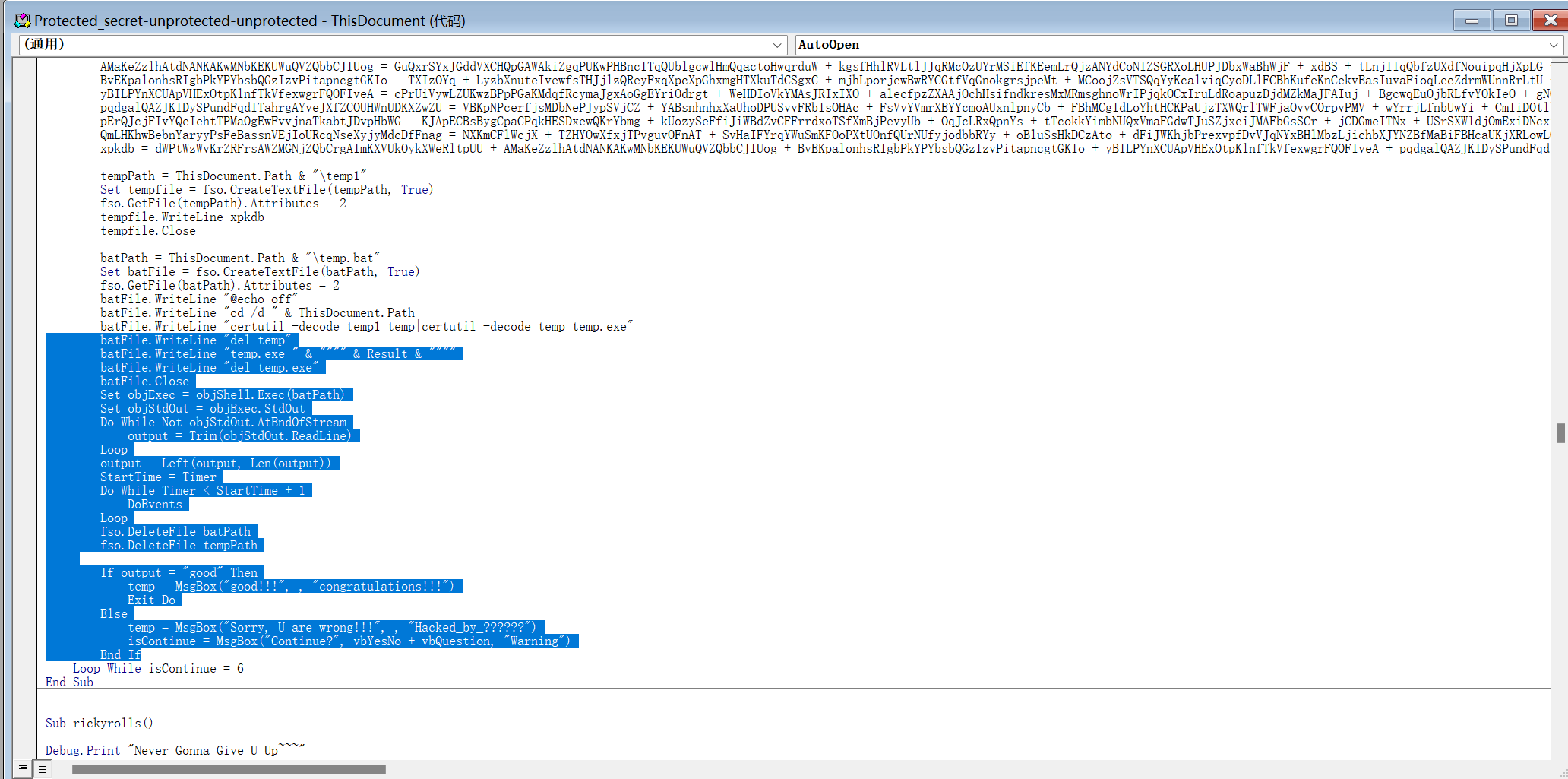
查看vb源文件,发现有操作del了文件,把它删掉,得到temp1文件

不知道是什么加密方法,把docm拖到沙箱里

两次base64得到mz开头的文件,下载下来
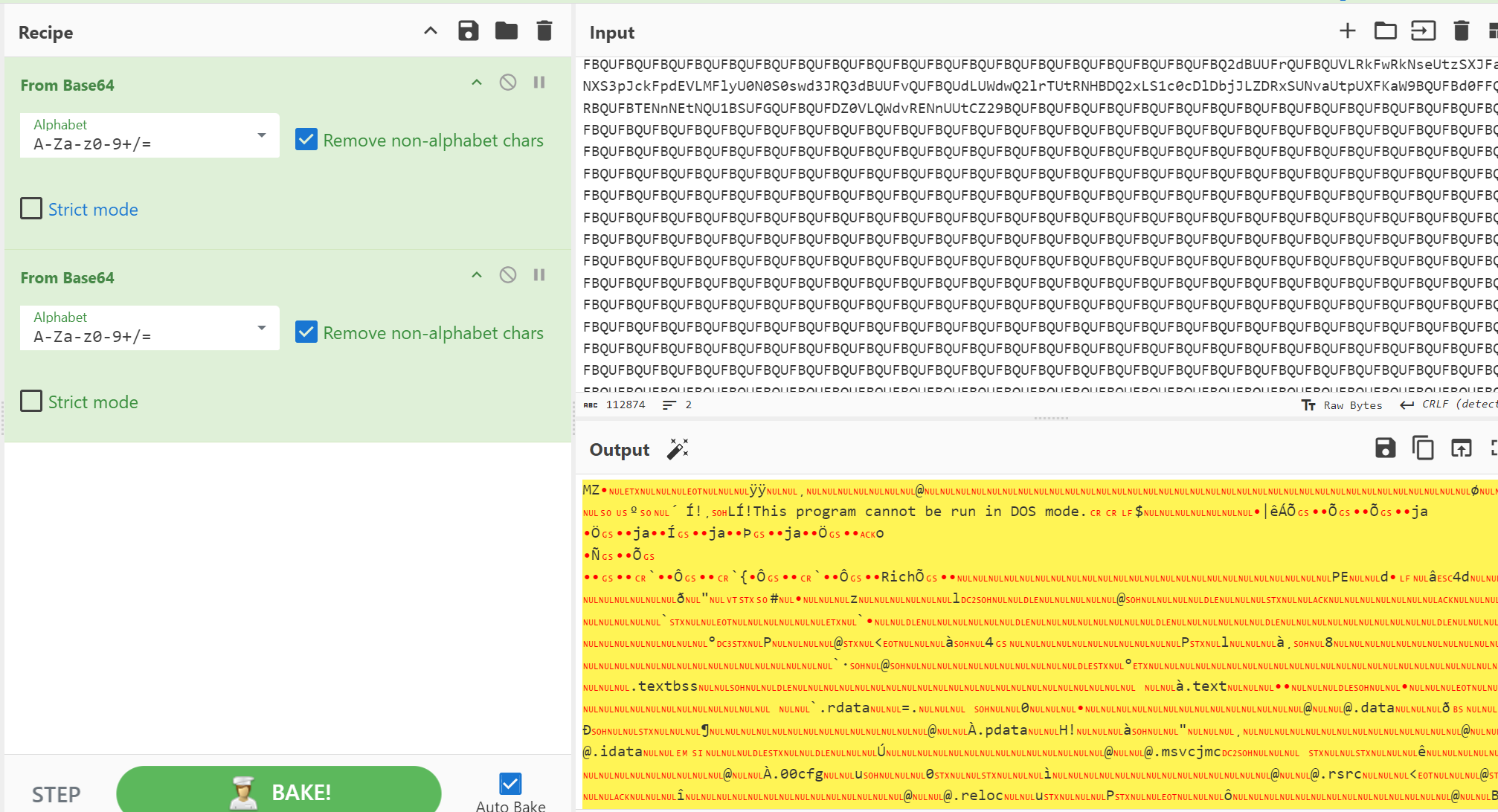
拖到ida里
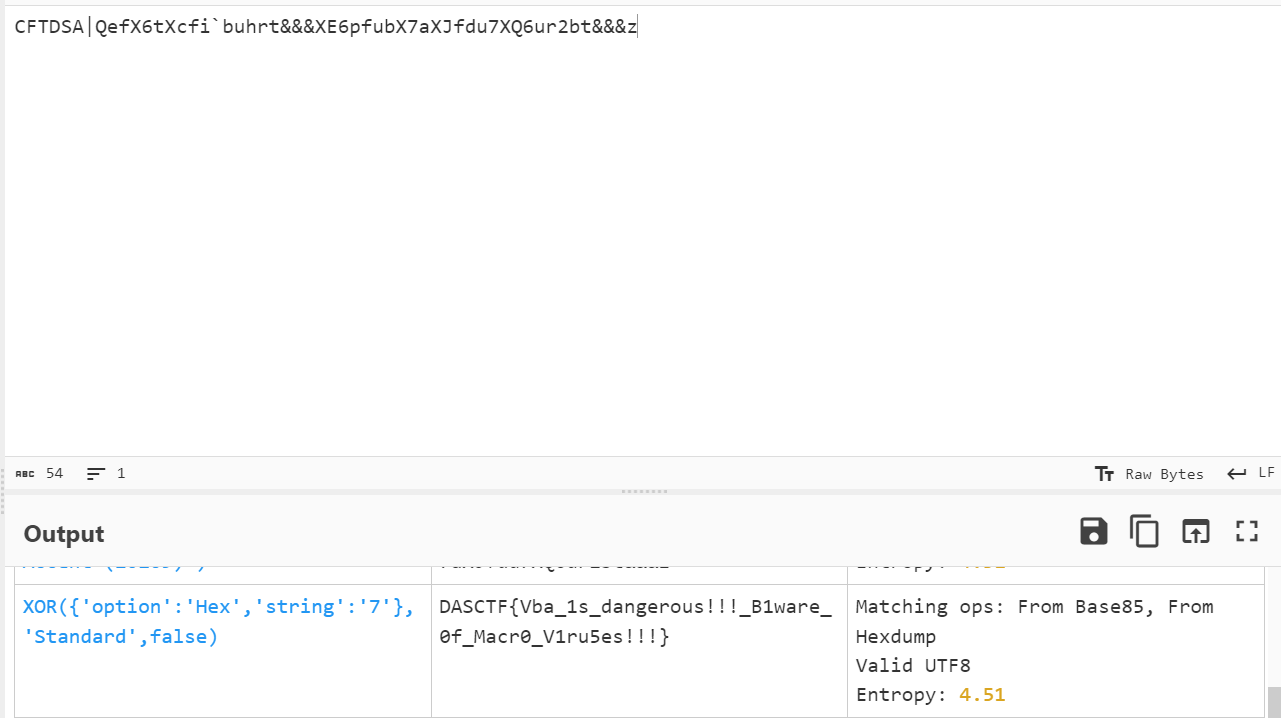
就是简单的位移
EXP:
1 | |

cyberchef里magic就能得到flag
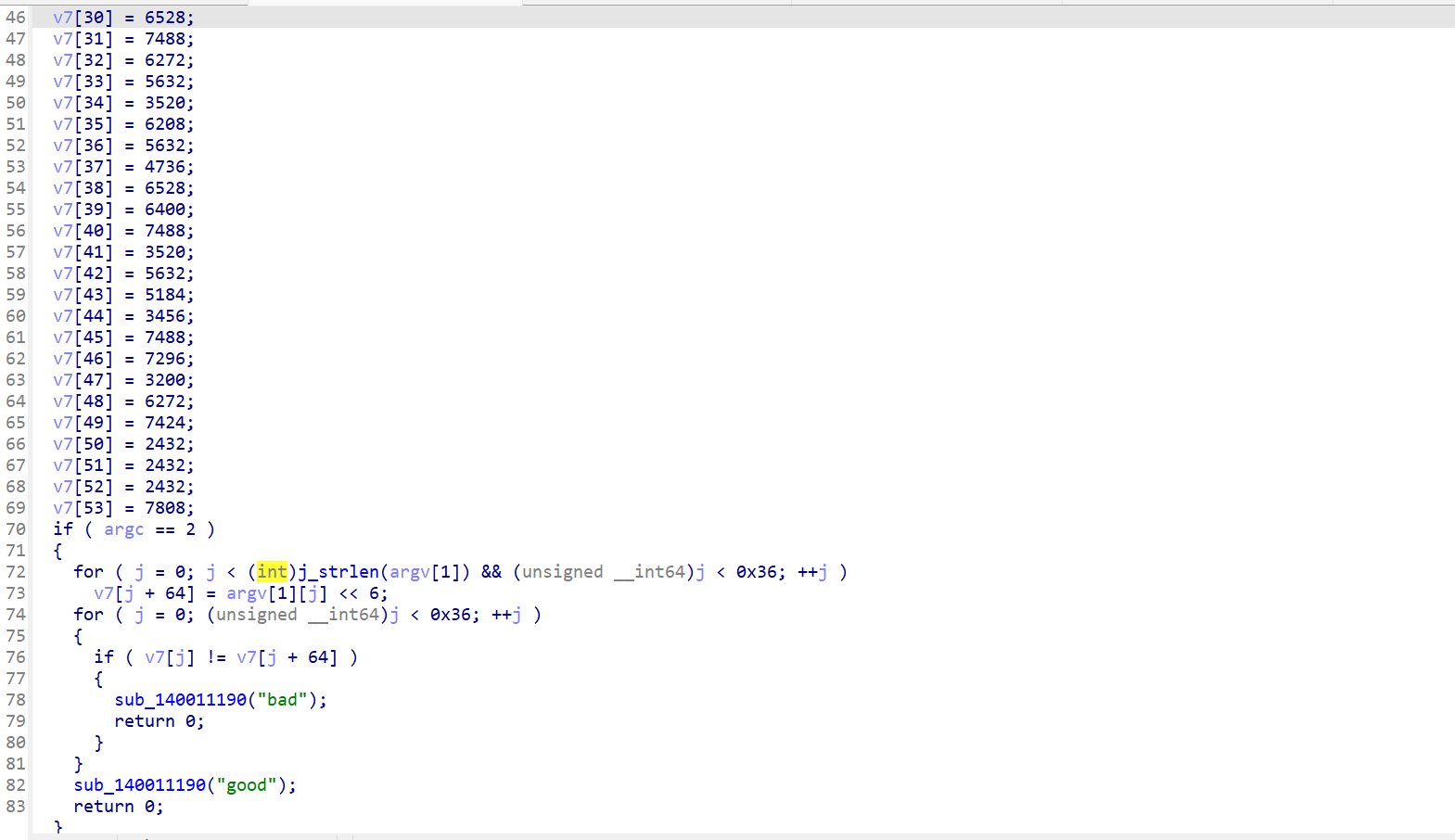
你这主函数保真么
首先找到真正的主函数
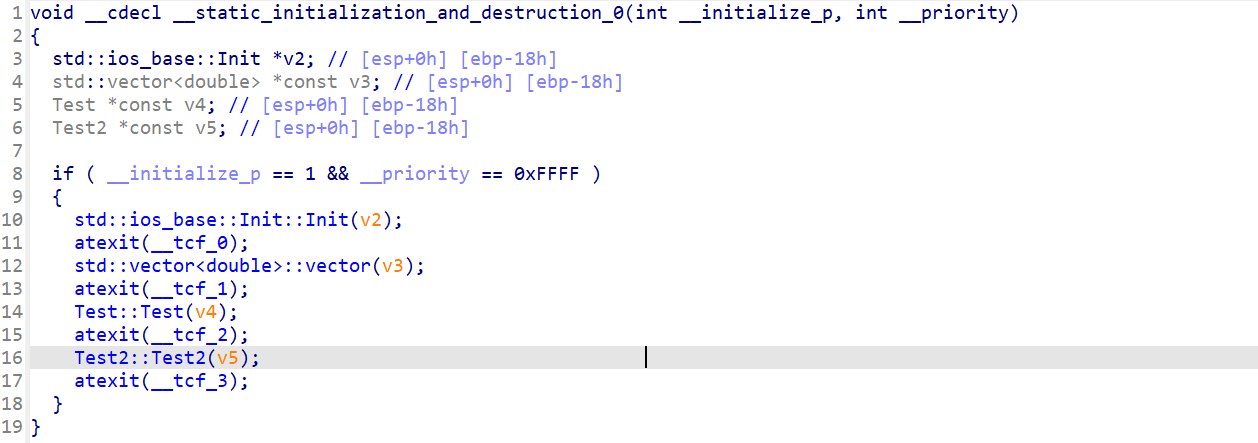
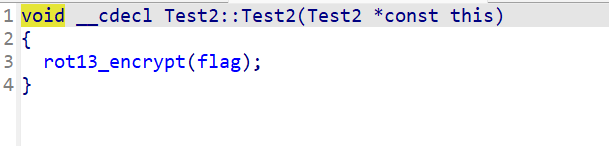
一个简单的离散余弦的逆变化和一个四舍五入,别忘了test2最后是一个rot13
1 | |

AI
NLP_Model_Attack
AI 攻击, 暴力美学
1 | |
直接逐位爆破, 然后判断, 一位不行两位, 能够爆破出来正确的
数据安全
data-analy1
就是一个简单的还原EXCEL表
EXP:
1 | |
data-analy2
使用tshark将http流量导出

EXP:
1 | |
data-analy3
Talk is cheap, show me your code
(永远的 C#!Python 什么的都是渣渣)
1 | |